Reporting
Last updated on 2024-05-13 | Edit this page
Estimated time: 8 minutes
Overview
Questions
- What tools are available in the BCE for analyzing disk images or directories of data transferred from legacy media?
- How do you use them?
- Specifically, how can librarians and archivists capture basic system characteristics and metadata?
- How can they generate reports to help them triage and organize files for digital archiving processes?
- How can they scan for for potentially sensitive information to help them make decisiosn about access?
Objectives
- Gain basic experience with:
- Brunnhilde, a reporting tool for directories and disk images;
- Bulk Extractor and Bulk Reviewer, which scans for credit card numbers, emails, etc.; and
-
fiwalk, to print filesystem statistics
- Learn more about reporting functionality in the BitCurator Environment, in general, and where to learn more.
Reporting in BitCurator is essentially a method of generating technical and preservation metadata about a disk image or directory of data.
At a high level, you will be using, and creating a workflow piecing together:
- a “map” of the disk image, which records relationships, integrity (checksums), names, timestamps, etc. (this is in DFXML);
- a summary of the file types, duplicates, and other relationship information;
- tools for assessing Personally Identifialble Information (PII) and sensitive content; and
- summaries of sensitive content, if discovered.
Note: If you haven’t yet created a disk image or otherwise have a directory of data to work with, you can use Bentley Code4Lib Samples or download sample data from BitCurator’s Github site and work with that: bcc-dfa-sample-data.
One possible structure to group content and metadata (the one we’ll be using for this workshop):
c4l24_bicuratorintro_group0X_image0XX/ <-- parent directory (sample name)
│
├── reports/ <-- subdirectory for detailed metadata (use mkdir)
│ ├── beout/ <-- bulk extractor reports (generated by bulk_extractor)
│ ├── brunn_output/ <-- brunnhilde reports (generated by brunnhilde.py)
│ └── mappedfeatures/ <-- sensitive info (generated by identify_filenames.py)
│
├── c4l24_bicuratorintro_group0X_image0XX_dfxml.xml <-- DFXML (E01 “map” generated by fiwalk)
├── c4l24_bicuratorintro_group0X_image0XX.E01 <-- disk image (generated by Guymager)
└── c4l24_bicuratorintro_group0X_image0XX.info <-- disk image metadata (from Guymager) First Things First
Today we’ll be using a number of command line tools in the BCE, including:
fiwalkbrunnhilde.pybulk_extractoridentify_filenames.py
All of these are “pre-loaded” in the BCE, and a simple way to get
usage instructions for any of them is to simply type their names in the
terminal and press enter. E.g., brunnhilde.py, which is the
same as as using brunnhilde.py -h or
brunnhilde.py --help. This is standard for CLI tools, but
we hope it helps illustrate how what we’re doing today is only the “tip
of the iceberg” for any of these individual tools or the BCE in
general.
Reporting
BitCurator includes a variety of tools to analyze and report on disk images and the filesystems they contain.
Map Your Image AKA How to Create DFXML (with fiwalk)
Your first goal is to create a Digital Forensics or DFXML “map” of the disk image. DFXML is used to automate digital forensics processing, and includes all filesystem data, checksums for integrity, and explain the relationships of elements of the disk image. We’ll do this using fiwalk, a program that processes a disk image using the SleuthKit library (a library and collection of command line tools that allow you to investigate disk images for various file systems) and outputs its results in Digital Forensics XML. This map will be used later in other tools.
Tool: fiwalk
To run: Use fiwalk in the terminal.
Command syntax:
fiwalk -f -X <output filename_dfxml.xml> <input image file.E01> This command tells the terminal to run fiwalk, run the
“file” command on each file that it finds (-f), write the
results to an XML file with the specified filename
(-X <output filename_dfxml.xml>) and identifies the
source of the analysis (the disk image).
Generate File Summaries and Reports AKA How to Run brunnhilde to Report on the Disk Image
Your next goal is to create a summary of file types, duplicates, and any hard to identify files using Brunnhilde. Brunnhilde runs Siegfried, a signature-based file format identification tool, against a specified directory or disk image, loads the results into a sqlite3 database, and queries the database to generate reports to aid in assessment: triage, arrangement, and description of digital archives. The program will also check for viruses unless specified otherwise, and will optionally run bulk_extractor against the given source.
Tool: brunnhilde
To run: Use brunnhilde in the terminal.
Command syntax:
brunnhilde.py -d -b --tsk_fstype fat --tsk_imgtype ewf <image input file.E01> <output destination/reports/brunn_output> This command tells the terminal to run brunnhilde, treat
the input as a disk image (-d), generate a bulk extractor
report (-b), analyze the disk image as a FAT filesystem
(--tsk_fstype fat), and analyze the disk image as an expert
witness file (--tsk_imgtype ewf). Then, the command
provides the location of the source disk image
(<image input file.E01>) and the destination for
reports
(<output destination/reports/brunn_output>).
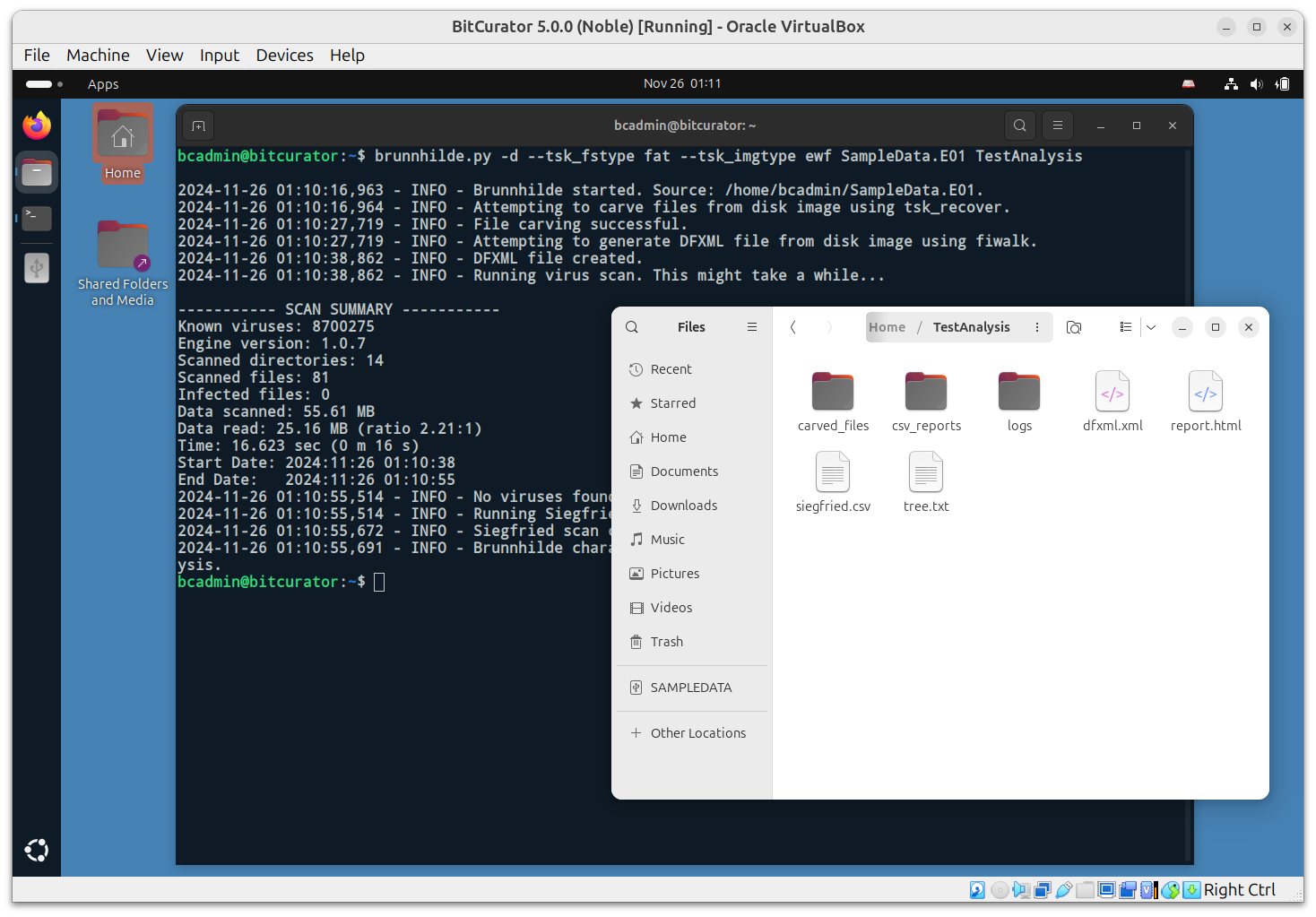
Outputs include:
- report.html: Includes some provenance information on the scan itself, aggregate statistics for the material as a whole (number of files, begin and end dates, number of unique vs. duplicate files, etc.), and detailed reports on content found (file formats, file format versions, MIME types, last modified dates by year, unidentified files, Siegfried warnings/errors, duplicate files, and -optionally - Social Security Numbers found by bulk_extractor).
- csv_reports folder: Contains CSV results queried from database on file formats, file format versions, MIME types, last modified dates by year, unidentified files, Siegfried warnings and errors, and duplicate files.
- siegfried.csv: Full CSV output from Siegfried
Identify Sensitive Information AKA How to Identify Features (with bulk_extractor)
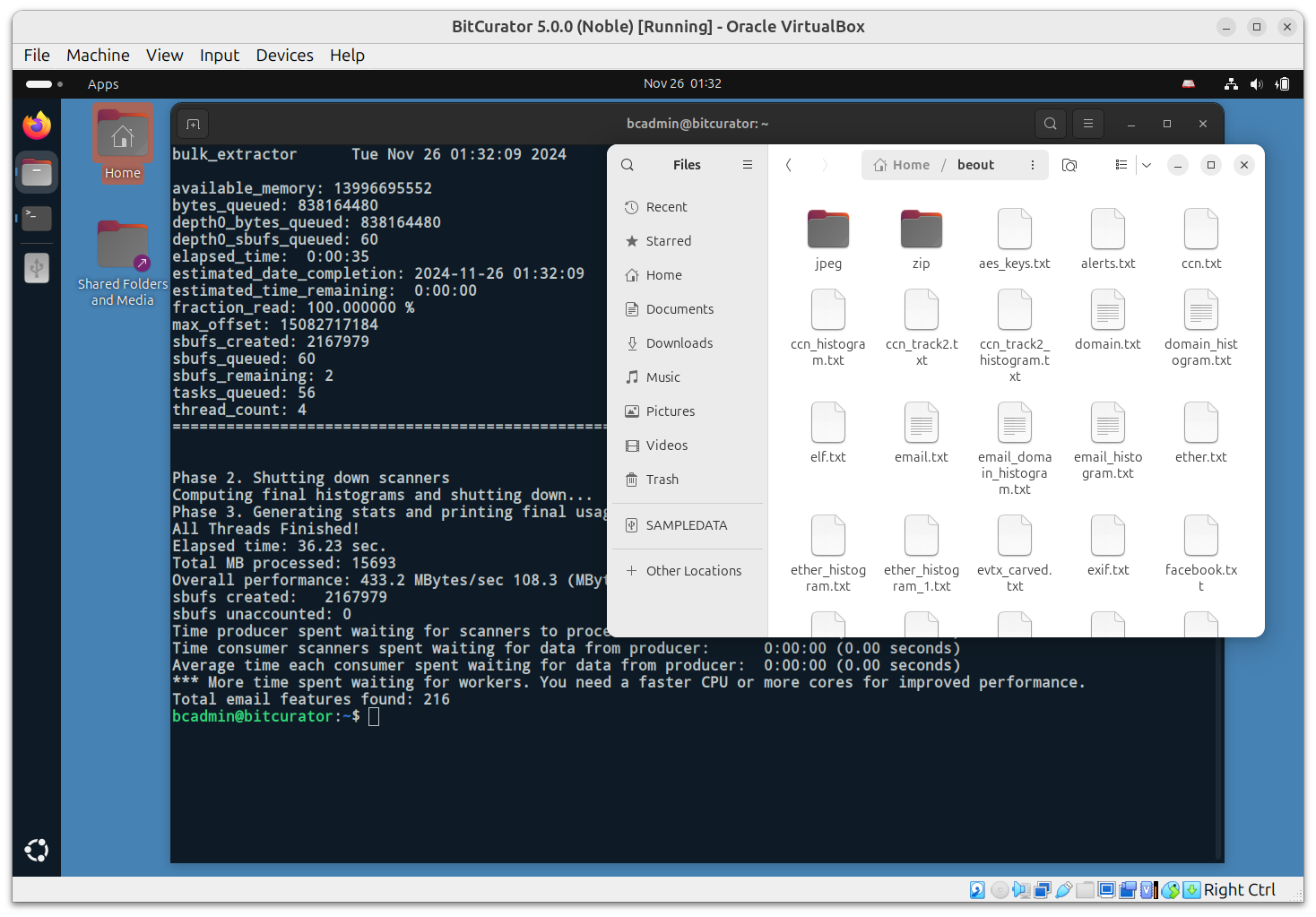
Your next goal is to create reports that identify potentially sensitive information, like SSNs, emails, etc. To do this, we’ll use Bulk Extractor, which rapidly scans any kind of input (disk images, files, directories of files, etc) and extracts structured information such as email addresses, credit card numbers, JPEGs and JSON snippets without parsing the file system or file system structures.
Tool: bulk_extractor
To run: Use bulk_extractor in the terminal AND/OR use Bulk Reviewer.
Command syntax:
bulk_extractor -o <output destination/reports/beout> <input target disk image file.E01> This command tells the terminal to run the
bulk_extractor tool, then to output a report to the
specified directory
(-o <image directory>/reports/beout) and specifies
the target file to analyze
(<input target disk image file.E01>).
Note: To use Bulk Reviewer, a GUI alternative and an Electron desktop application that aids in identification, review, and removal of sensitive files in directories and disk images, and which scans directories and disk images for personally identifiable information (PII) and other sensitive information using bulk_extractor, click over Applications (top left) > Forensics and Reporting > bulk-reviewer. Click “Scan new directory or disk image.” Select the “Type” (“Directory” or “Image”), create a “Name” for the report, “Browse” to the directory or disk image, select and “Options” and then click “Start Scan.” Once it’s finished, you can then view the report and have options to save or export the results.
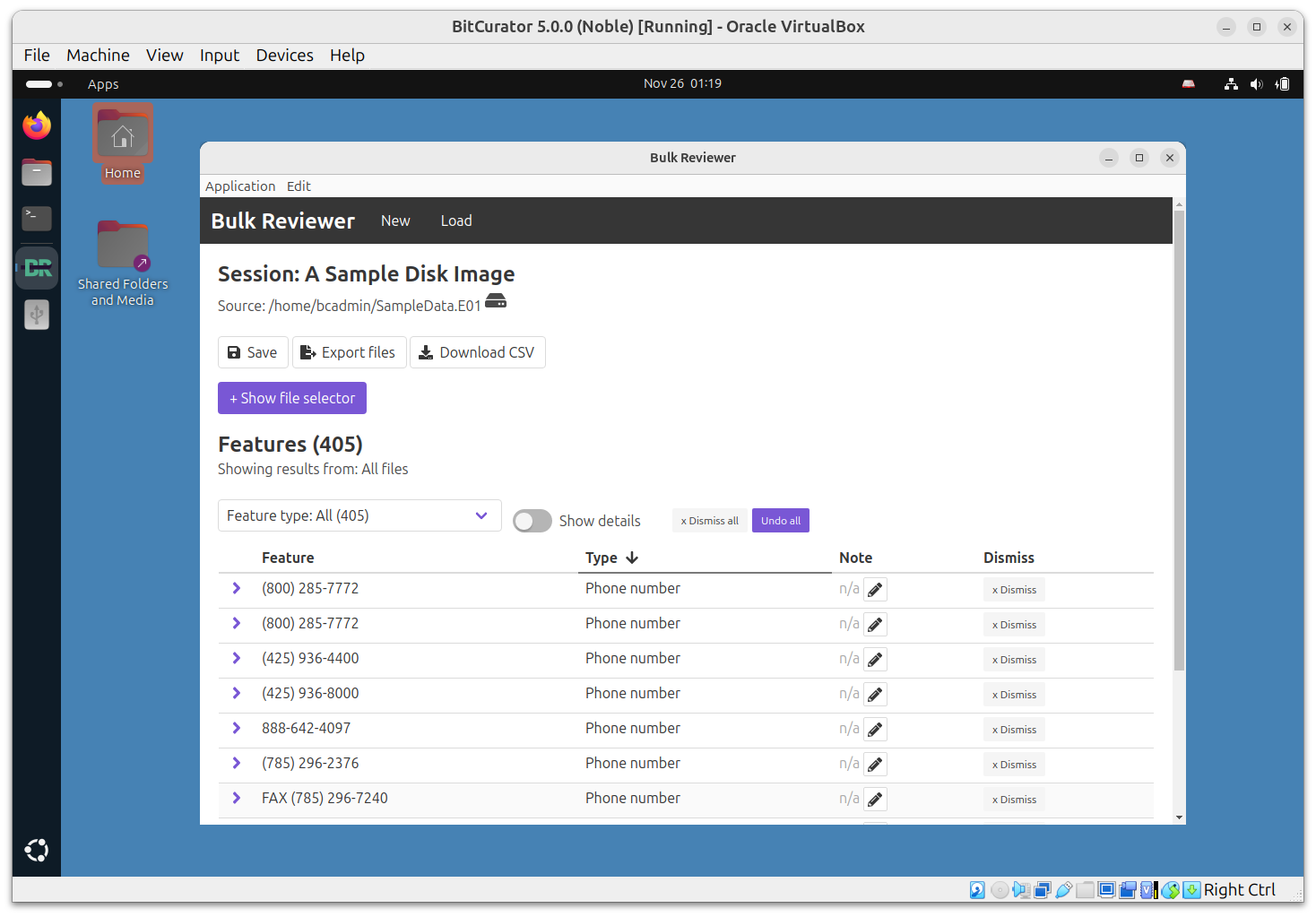
The desktop application then enables users to:
- Review features found by type and by file in a user-friendly dashboard that supports annotation and dismissing features as false positives
- Generate CSV reports of features found
- Export sets of files
- Cleared: Files free of PII
- Private: Files with PII that should be restricted or run through redaction software
Note: The “terry-work-usb-2009-12-11.EO1” disk image in the sample data from BitCurator’s Github site produces a number of “hits”–including social security numbers, phone numbers, and email addresses–if the directories or disk images you’re working with do not.
Summarize Sensitive Information Reports AKA How to Summarize Identified Features (with identify_filenames.py)
Your final goal is to summarize the reports on sensitive information,
show main types of features, and to note what files contain the
features. To do this, we’ll use identify_filenames.py,
which identifies filenames from “bulk_extractor” output and uses the
DFXML to map to point between various hits discovered earlier to the
files on the disk images (rather than the byte offsets).
Tool: identify_filenames.py
To run: Use identify_filenames in the terminal.
Command syntax:
identify_filenames.py --all --image_filename <input disk image.E01> --xmlfile <DFXML of the image_dfxml.xml> <bulk extractor reports location/reports/brunn_output/bulk_extractor> <destination for summary report>/reports/mappedfeatures> This command tells the terminal to run the
identify_filenames.py script, look at all of the feature
files (--all), specifies the source image
(--image_filename <input disk image>), use the
specified DFXML file
(--xmlfile <DFXML of the image_dfxml.xml>),
identifies the bulk extractor output to use
(<bulk extractor reports location>, use the one in
<image directory/reports/brunn_output/bulk_extractor>),
and specifies a destination for the the analysis
(<image directory/reports/mappedfeatures>).
So What?
What is the utility in creating all these reports? Reports create technical and preservaton metadata about directories or disk images that can accompany them in to the future and aid in later appraisal and processing for preservation and access.
Key Points
- Some reports may be needed for contextualizing and using the disc images in other programs (dfxml).
- Some reports may be more for risk management and analyzing PII.
- Some may be more for preservation planning (file types).
- Some may be for general description (dates of creation, titles/names of files, users, or other topical information).
The way you’d interpret any of these reports depends on the report on what you’re wanted to get out of it. Some reports, like the bulk_extractor reports, are easier to read through. The DFXML, while “harder” to read, gives you all the checksums and a listing of what’s on a disk image, which could be good for checking fixity, but also helping you to determine if you want to extract the files from the disk image.
Additional resources
- BitCurator Quick Start Guide, which includes sections on:
- Jesse’s BitCurator Workstation Guide created for SI 667: Foundations of Digital Curation.
- Brunnhilde - Siegfried-based characterization tool for directories and disk images, for more information on Tessa Walsh’s Brunnehilde tool.